The other day several of us where having a discussion about AutoCluster, which employs In Common With (ICW) matches, and AutoSegment cluster, which employs overlapping segments and triangulated segment. Triangulated segments, where you and some of your matches share the same segment on the same location of a particular chromosome, indicate that you share a common ancestor. A segment of DNA can only come from one ancestor. Then it’s a matter of determining which ancestor gave you that segment.
ICW clusters are groups of matches that share many if not all matches but they do not necessarily share one common ancestor. The question then came up if matches are in a cluster together, doesn’t that automatically mean they all share a most recent common ancestor (MRCA). Like so many things, it depends.
In many cases I’ve been able to classify an ICW cluster to a specific grandparent or great grandparent. But then there are some where there’s a mixture of generations, a great grandparent and that person’s parents, for example. Those seem to be the ones that I see most often. There is a common ancestor, but not everyone in the cluster has the same most recent common ancestor. Recent being the key word there.
My family is such that I have a large number of unknown DNA matches. I’m an only child. My parents did not do DNA testing. My closest known cousins are 2nd cousins. Most often I’m looking for fourth or more distant cousins.
Maternal 3rd and 4th Great Grandparents
The AutoCluster in figure 1 is from 23andMe. I found person A early on as a DNA match. She has tested on several sites. We emailed back and forth, and I was able to add her to my tree. The next one I found on 23andMe was person E. We also emailed, and I was able to place him in my tree. Filling in other descendants from the same line with the help of cousin’s trees I had all the others in my tree before they showed up as DNA matches. A mini tree that shows how they are all connected to me is in figure 2.


This is my mother’s mother’s side of the family. I’m circled in the tree in figure 2. My grandmother, Louise Wolff, was the daughter of Jacob Wolff and Anna Marie Briel. Both were born in Marburg, Germany and immigrated to Richmond, VA. A number of Anna’s cousins on her mother’s side had already immigrated to Richmond. In the tree Anna Briel’s parents were Phillip Briel and Elizabeth Schaaf, my 2nd great grandparents. All but one of the matches in the cluster descend from Phillip and Elizabeth. Person H descends from Elizabeth Schaaf’s parents Matthaus Schaaf and Anna Kuntz.
I like to use the Cluster Auto Painter (CAP) and add my cluster results to DNA Painter. Figure 3 shows the segments from this cluster.

The segments are labeled the same as in the cluster (figure 1) and the tree (figure 2). Each segment of DNA that you inherit comes from only one ancestor. Most of the time I name them for ancestor couple because I don’t know which of the couple gave the segment to me.
The segments on chromosome 10 and 12 are where person H matches me. Because the MRCA between H and me are my 2nd great grandparents, I would move those to a new group named for Matthaus Schaaf and Anna Kuntz. Then I’d change the cluster name for the rest of these matches to Phillip Briel and Elizabeth Schaaf. Clearly A, B, C, and D on chromosome 10 got that segment that they share with me from my 2nd great grandmother, Elizabeth Schaaf, and she got it, as did H from her parents. I name my groups based on couples, and I have no way, at the point, to tell if that segment came from Elizabeth’s father or her mother.
How was I able to figure all of this out? First one of my Schaaf 4th cousin has been researching and documenting the family a lot longer than I have. A lot of the information in my tree came from her research. When I noticed a match to person A first on FTDNA, I emailed her. That helped me fill in some of the living people in her part of the family. Person E matched on 23andMe, and because of his triangulating with A and me, I knew he was in this part of this same family. I messaged him, and he helped me fill in his family. When person B appeared I knew right away where she fit because her mother and mine had been good friends. So really it came down to having a good, filled out tree and matches who replied and shared information with me.
Paternal – Somewhere on the Byrnes line
I don’t always have such luck in getting replies to messages. Figure 4 shows a perfectly filled AutoCluster from 23andMe that my paternal 2nd cousin, Trish, is in.
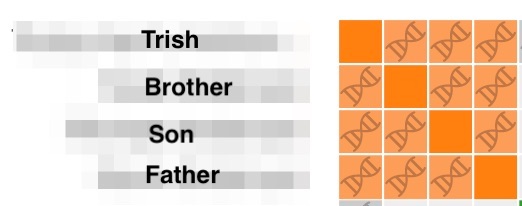
The 3 others in the cluster are a father, his brother and his son. The son was the first to show up as a match to me, sharing 36 cM. According to the shared cM project 36 cM is the average for 4th cousins, so that would be around the 3rd great grandfather level. His father also shares 36 cM and his uncle shares 39 cM. He’d added a greeting on his page and wanted people to message him. He also indicated that he lives in the same city where I grew up. I messaged him 3 years ago but never got a reply. About a year later his uncle showed up as a match. I messaged him 2 years ago and again no reply. By now Trish had tested and I could see that they matched her, so I knew it was on my father’s mother’s side. The father only showed up recently, and I messaged him last week. He also added 3 ancestor surnames. Unfortunately the surname of my matches here is rather common. I tried looking for each of them on Ancestry and found over 900 members with the same name. Then I tried looking for trees with combinations of their surname and the 3 surnames the father had listed. Still that didn’t help.
The 3 of them share 2 segments of DNA with me. They triangulate with Trish on chromosome 17. I know that triangulated segments with Trish could be Byrnes, Fenton, Lillis, Shannon or O’Brien. I’ve not resolved which is the chromosome 17 segment. The other segment that the 3 of them and I share is on chromosome 1, see figure 5. I do know something about that segment! Four years ago I found 6 people on GEDmatch that triangulated with each other and me on that segment and emailed them. I heard back from several of them. One of their grandmother’s was a Byrnes, and several of them had ancestors from County Galway near the County Roscommon border! Thomas Byrnes, Trish and my great grandfather was from County Roscommon, but we don’t know exactly where in Roscommon. This gives us a hint to where he lived. I’ve not been able to find a baptismal record for Thomas, so I know he lived in an area where the baptismal records have not survived. All I can say for this cluster is that I know at least 1 of the segments is on our Byrnes line, and it’s likely around the 3rd great grandparent level or more distant. Since Trish and my MRCA are our great grandparents, there are at least 2 different MRCA in this cluster.

Dave’s Paternal Grandmother’s Line
My husband Dave has a large number of known cousins on his paternal grandmother Marti side, and many of them have done DNA tests. Dave’s Aunt Mary worked on the family tree for many years, and we can trace back several generations. Figure 6 shows one of Dave’s AutoClusters from MyHeritage.
At first I thought this was going to be similar to my Schaaf one since there’s a combination of 2nd and 3rd great grandparents. But as soon as I drew out the tree I knew something was different here. Figures 7 and 8 show the trees for this cluster.
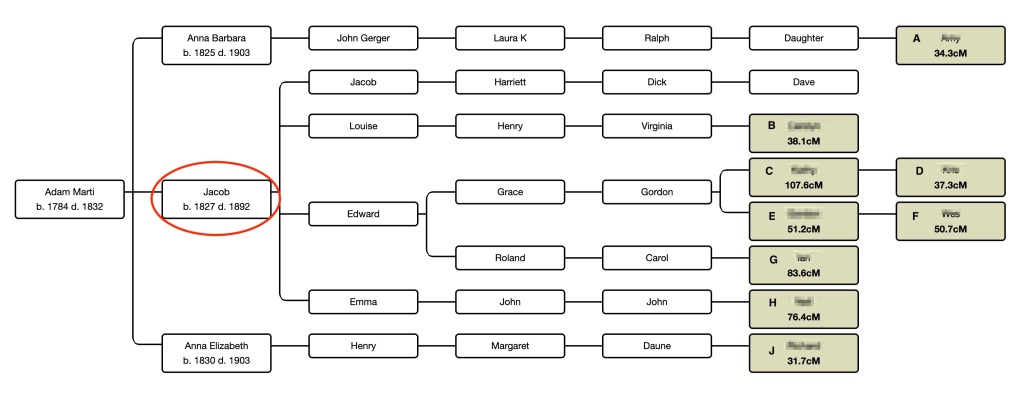
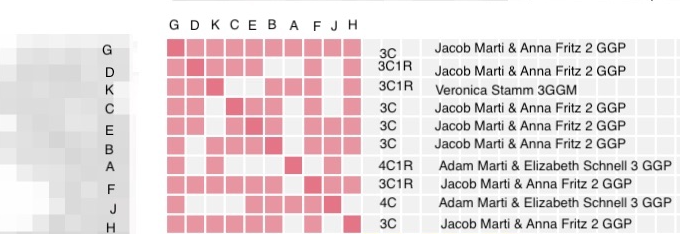
Dave’s paternal grandmother Harriett’s father was Jacob Marti, son of Jacob Marti and Anna Fritz. The elder Jacob’s parents were Adam Marti and Elizabeth Schnell. Now the problem coms in that match K descends from Veronica Stamm, who is Anna Fritz’s mother. After Veronica’s husband, Johann Fritz died, she remarried and had daughter Rose, who was a half sister to Anna Fritz. Match K descends from Rose.

Dave and matches B through H MRCA are his 2nd great grandparents, Jacob Marti and Anna Fritz. His MRCA with matches A and J are Jacob’s parents, Adam Marti and Elizabeth Schnell, and his MRCA with match K is his 3rd great grandmother, Victoria Stamm. Person K matches B through H with Victoria Stamm as their MRCA. All of this would be very well as long as K doesn’t match A or J. However, K does match A. There has to be some more distant connection between Victoria Stamm’s family and the Marti family. Matches A and K share 32 cM and do not triangulate with Dave. From the shared cM project 32 cM would be in the 4th to 5th cousin or more distant range. Veronica Stamm was born 1811, so the MRCA ancestor here is the 1700s. All of these families were living in the same village in Switzerland at that time, so it’s quite possible that there were other earlier marriages in the family that we don’t know about.
Conclusion
This started from a question about whether or not all the matches in an AutoCluster were from one most recent common ancestor. In my experience and the examples I have shown here, they are not. There is a family line, such as the paternal grandmother, that all the matches follow, but there are typically several generations of ancestors present in the cluster. How do you figure out the exact connections? What I’ve found is having a detailed tree, matches that also have detailed trees, as well as matches that will reply to messages and share family information with you are important to helping to find that common ancestor.
Considering the fact that the clustering was performed using shared matches, this conclusion perhaps should not be a surprise. Shared match data is usually a mixture of DNA matches that share the same or another segment as compared to you. However, the AutoSegment ICW, which is available for FTDNA and 23andMe, and AutoSegment for GEDmatch, which employs triangulated data, looks for overlapping segments that are on the same side. Therefore, by using these clusters, we should be able to obtain clusters of matches that share the same or several DNA segments and therefore share a common ancestor. The AutoSegment ICW clusters will be explored in a future blog.
Both Dave and Trish have giving me permission to use their real names. All other living people’s names are hidden for privacy.

Assuming no endogamy (and yes I know that is more common than many may think) If I have 5 matches in a cluster: 3 being a person and his two kids who I know are related to me through my paternal line, and 2 which I do not know how they are related. Must the 2 be through my maternal line or could they show up because they are matching my maternal side of that particular chromosome and segment.
To put it differently, can autoclusters mix and match segment matches from the paternal and maternal copy of the chromosome…..to put paternal and maternal matches in the same cluster.
Ultimately, I am trying to figure out whether it is enough to know that at least one match in a cluster is paternal, to conclude (again absent endogamy) all the other matches in that cluster also are paternal.
LikeLike
An AutoCluster is based on your in common with or shared matches, so all of the ones in a cluster would be on the same side of your family. Yes, knowing that one match in the AutoCluster is paternal would tell you that all the others in that cluster are also paternal.
A different situation is an AutoSegment cluster where all the matches that are on a specific segment would be grouped together. That could be a mixture of paternal and maternal matches that happen to fall on the same segment of a chromosome.
LikeLike
Hi, I have unknown heritage and was wondering how to interpret my AutoCluster analysis from MyHeritage. The minimum shared DNA threshold for the matches in each cluster is 10 cM, and minimum shared DNA between me and my matches s 15 cM. I have 22 clusters in total.
I know that distant matches are hardly worth studying, but is it valid to assume that connected clusters no matter how distant – using grey squares in the report and distinct ethnicities of the cluster as connectors – represent each unique grandparent line?
My first cluster, which has 18 people in it that appear to be of German descent (largest match shares 27 cM with me), seems to be connected to 3 other smaller clusters through grey squares.
My second largest cluster (8 Finnish people, an endogamous group, largest match shares 23 cM) has grey square connections to 13 smaller Finnish clusters in the report.
My 4th largest cluster has 6 Turkish matches (largest match sharing 22 cM) who connect to one smaller Turkish cluster in the report.
My fourth possible grandparent group seems to be two separate small clusters (3 people in each, though the largest match in one of them shares 69 cM with me) who show Armenian ethnicity (the two clusters do not connect with grey squares for some reason even though this group is known to be endogamous).
There are no clusters left in the report that are unaccounted for in terms of placement in a possible grandparent group.
I know that MyHeritage tries to ultimately show grandparent lines no matter what the threshold adjustments are for each kit, so was wondering if my observations are legitimate? Is it valid to combine clusters using grey squares to form a distinct grandparent line this way no matter how distant these matches are? Or can even combined clusters (not one but many clusters) of matches represent a distant family branch like great-grandparent and further? Any insight would be greatly appreciated.
LikeLike
Hi Fran, Actually MyHeritage makes clusters with max 400 cM and adds about 100 matches with the minimum cM being wherever it ends up at that point. If no one on one of your grandparents line has done a DNA test, you won’t find any matches that fit for that line. Unlike when you do a manual Leeds chart or such and aim for 4 grandparents, that is not the case here. I ran a MyHeritage cluster this afternoon and have 19 clusters. The first 6 clusters appear to be on my paternal great grandmother’s side. Cluster 7 is my Dad’s father’s side. Clusters 8, 9, 10 and 11 I have no idea how we connect. Cluster 12 is my maternal great grandfather’s side. What I do is to build out trees for my DNA Matches and try to get back to a common location with one of my ancestors or a common ancestor.
One thing I like to do is to take the MyHeritage cluster and re-cluster it on Genetic Affairs to see if it does a better job of combining the grey cells into a cluster. I also like to do a screen shot of the clusters and draw lines to represent different parts of my family. Look at the matches and see if they have trees to help you figure out the connection.
LikeLike
This is really interesting, Patricia! Thank you for sharing your results. I am curious, when you say clusters 8,9,10 and 11 are mysteries, you mean even after having looked at the trees for those matches you still have no idea what lines it may be in your family? I know researching trees helps, but not always. There are people with brick walls and no common surnames found even with the help of extensive trees of the matches..
Also, I am surprised that your Dad’s father’s line is all the way in cluster 7 (not one of the first few). How many people are in that cluster 7? I ask because I thought the more people there are the more recent the family line could be?
LikeLike
Cluster 8 has a couple surnames that are likely Irish so my Dad’s side of the family. Cluster 9 and 10 I can’t tell. Cluster 11 I think is German, but I have a German paternal great grandmother as well as all my mother’s side is German. So I can’t tell which it is. Cluster 7 has 6 matches. Known 2nd cousin on my Dad’s father’s side. Three of those 3 I know exactly how they fit in my tree and our most recent common ancestors are my paternal great grandparents. Cluster 6 has another known 2nd cousin on my Dad’s mother’s side. Cluster 1 is O’Brien which is my Dad’s father’s mother’s mother’s side – my 3rd great grandmother was Johanna O’Brien. I’ve so far been mainly researching my Dad’s Irish ancestors. I’ve not started digging into my German ones yet. MyHeritage clusters are in order of number of people in the cluster. There are 10 in my cluster 1, down to 3 in clusters 15-19.
LikeLike
I see it gets very random and quite tricky.. What is the proper cM threshold (shared DNA amount) to determine whether or not the clusters are real and not false positive or identical by chance? Since MyHeritage automatically assumes the best threshold I am not sure which clusters I should be researching, because my matches on most of my clusters share on average less than 20 cM with me (the min value is 15 cM).
LikeLike
I use data down to 7cM, knowing that there’s about a 50% chance the 7 cM could be a false match. Because I know that all of my cousins will be 3rd or more distant I find this works for me. You might want to look at the new feature AutoKinship on Genetic Affairs with your clusters as well.
LikeLike
Thank you, will take a look!
LikeLike
Hi Fran, I just published a blog about using AutoKinship with MyHeritage data.
LikeLike