-
A Quick Note: AutoLineage Trees
There are times when I think I don’t have a tree for a certain DNA match and will add one, only to discover that there was already a tree there. Especially if the tree was added automatically, and I can see how to add another generation or so to it. One way to check your…
-
Using ChatGPT to Streamline DNA Analysis in My Coleman Research
David Coleman, my husband’s third great grandfather, was born about 1801 somewhere in Ireland. This information comes from the 1850 Federal Census — the only record we have includes these details about him. He married Catherine, likely in Ireland, though her maiden name is unknown. By 1820 they were in Saratoga, New York, where oldest…
-

New Copy and Paste Option in AutoLineage
Great news for AutoLineage users! You no longer have to use “Save Page As” to import your Ancestry matches and shared matches—there’s a faster way with simple copy and paste. Instead of saving files to your computer, you can now copy your match or shared match page in Ancestry and paste it directly into AutoLineage…
-
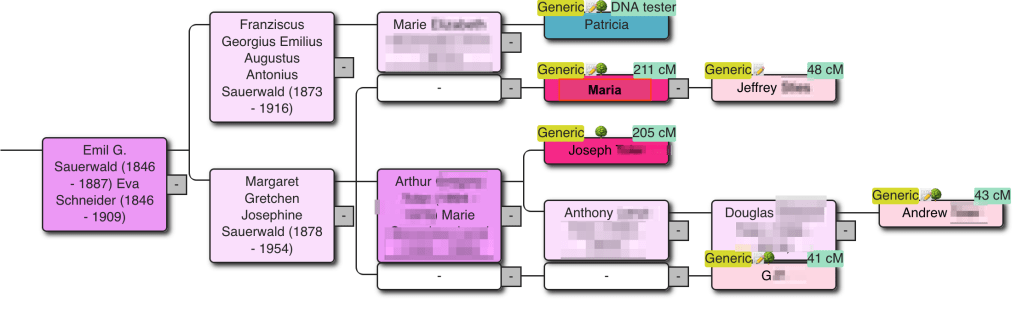
AutoKinship for MyHeritage and Ancestry: From Matches to Reconstructed Trees
AutoKinship generates a probability tree based on the DNA shared between matches. Within AutoLineage, this probability tree can be enhanced using reconstructed family trees, resulting in the refined outcome shown here. AutoLineage now includes a powerful new feature: the ability to predict trees based on DNA using AutoKinship on any cluster—even one with just two…
-
Exhaustive MRCA Analysis for GEDmatch Matches
A new import tool has recently been added to AutoLineage, enabling the use of GEDmatch Tier 1 data. This powerful addition allows users to identify potential common ancestors based on tree data linked to up to 7,500 matches. Unlike existing tools (even the ones on GEDmatch) that typically only analyze trees for a small number…
-
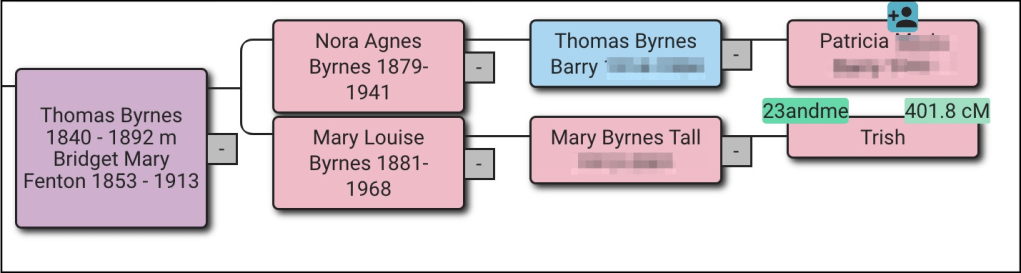
More Shortcuts for AutoLineage
Often your research is focused on a specific part of your family line. This was the case with Mary who wanted to explain her father’s Collins line. Where had the Collins family lived in Ireland? When did the immigrate to the United States? And could we find more cousins on the Collins line? She had…
-
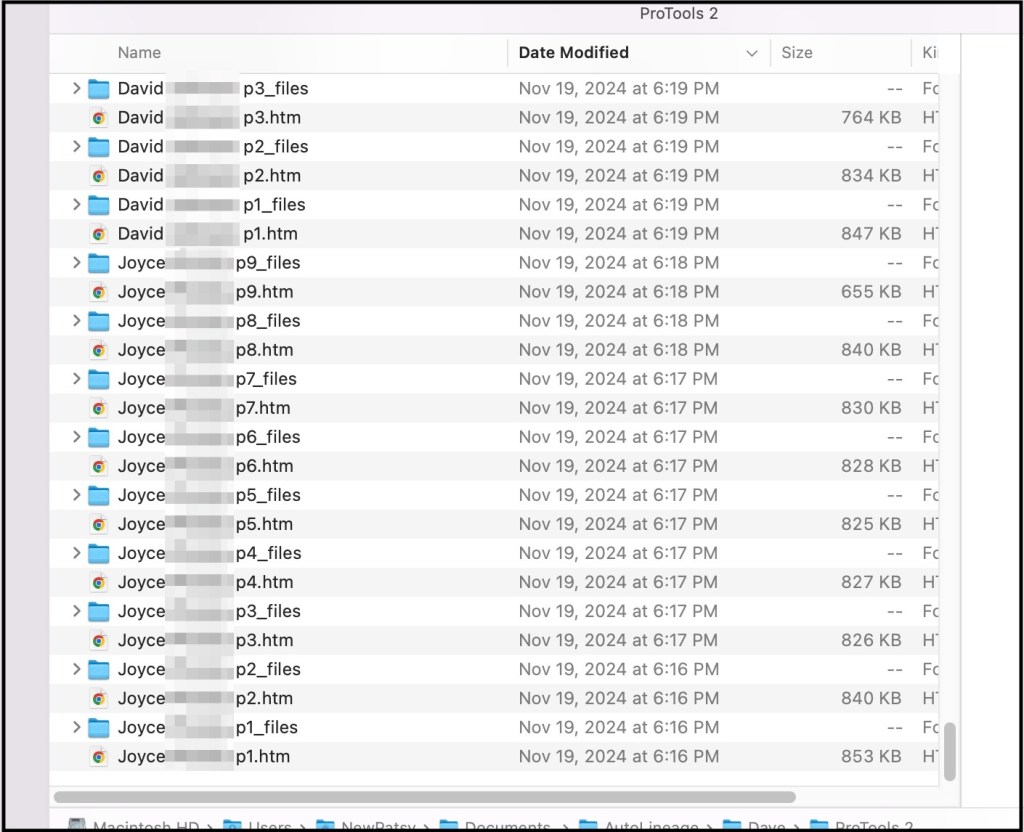
A Shortcut for Saving Pro Tools Shared Matches
If you have been collecting your Pro Tools shared matches for AutoLineage, you know it can take a bit of time. I’ve found another shortcut to speed up this collection. First I check if the match has a tree and look at the tree. If it’s only a few people and all are private, there’s…
-
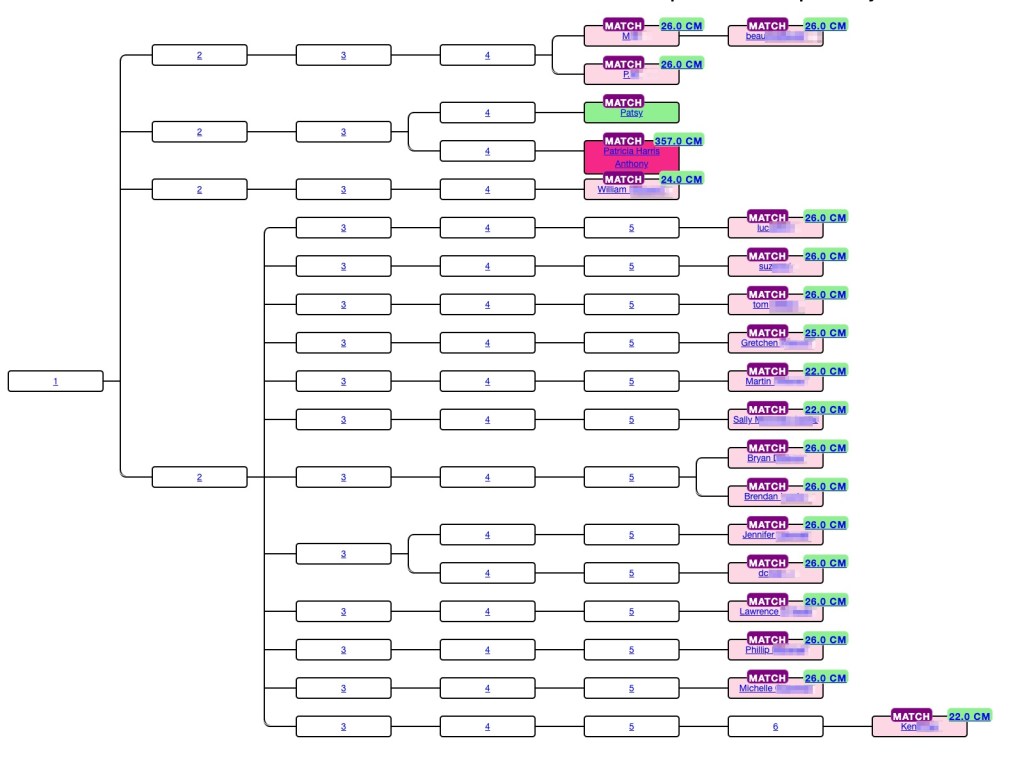
Convert Ancestry ProTools to Trees using AutoLineage and AutoKinship!
Genetic Affairs has unveiled a powerful new feature in AutoLineage—now you can apply AutoKinship to each individual cluster generated from Ancestry ProTools shared matches, unlocking a whole new level of insight into your family connections! It invokes the functionality of AutoKinship on the site directly at no additional cost, to provide reconstructed trees based on…
-
Pruning Your Trees in AutoLineage
I like to have pretty trees when I run ‘Find Common Ancestors’ on AutoLineage. But sometimes they turn out very messy. This blog will describe why that happens and how to fix it. The most common occurrence is when a match has more than one tree. I know that my second cousin (2C) Trish has…
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
