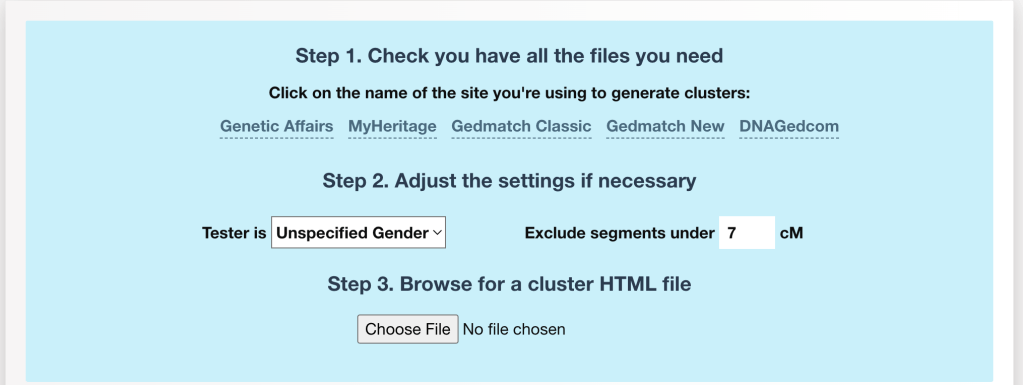
AutoLineage is a powerful tool that allows you to cluster your matches at a particular testing site but also to find common ancestors across multiple sites. In this blog, we will discuss a scenario when only data from FamilyTreeDNA (FTDNA) and GEDmatch can be used as sources, for instance for an investigative genetic genealogy search.
We will be importing and analyzing data from FTDNA and GEDmatch, and use the common ancestor identification tool to find common ancestors. Also, we’ll show how to use the hints tool to get insights about ancestral lines that could hold a potential common ancestor.

From the landing page select ‘Register a new Profile’ in the left panel. Start AutoLineage by making a profile for the case you are investigating and for whom DNA matches are obtained. In this blog, we shall be using Dave as an example.

Family Tree DNA
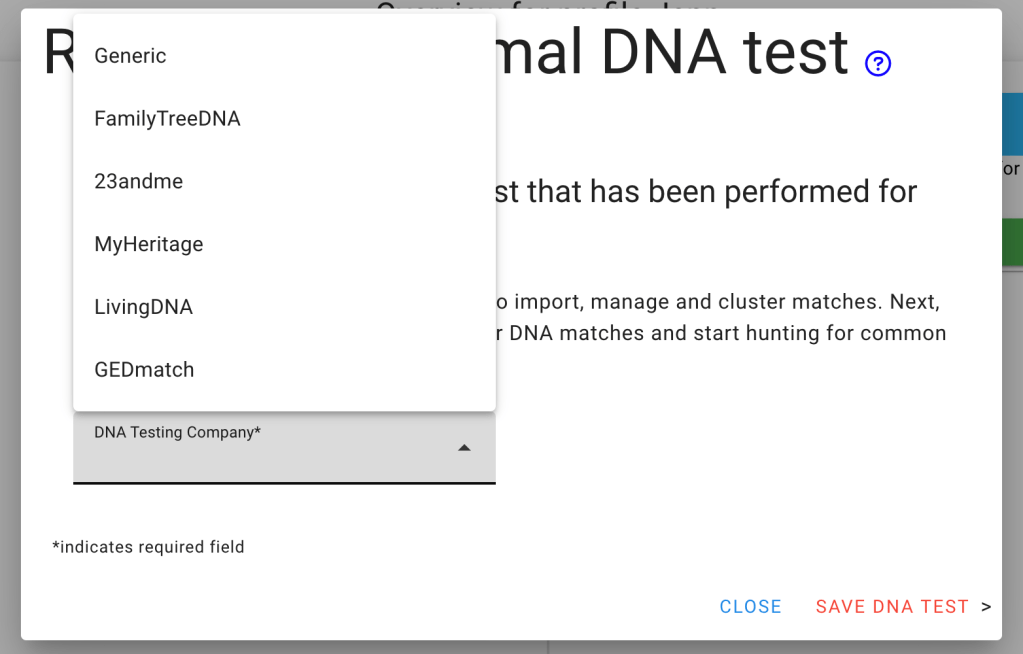
Next, a DNA test is registered.
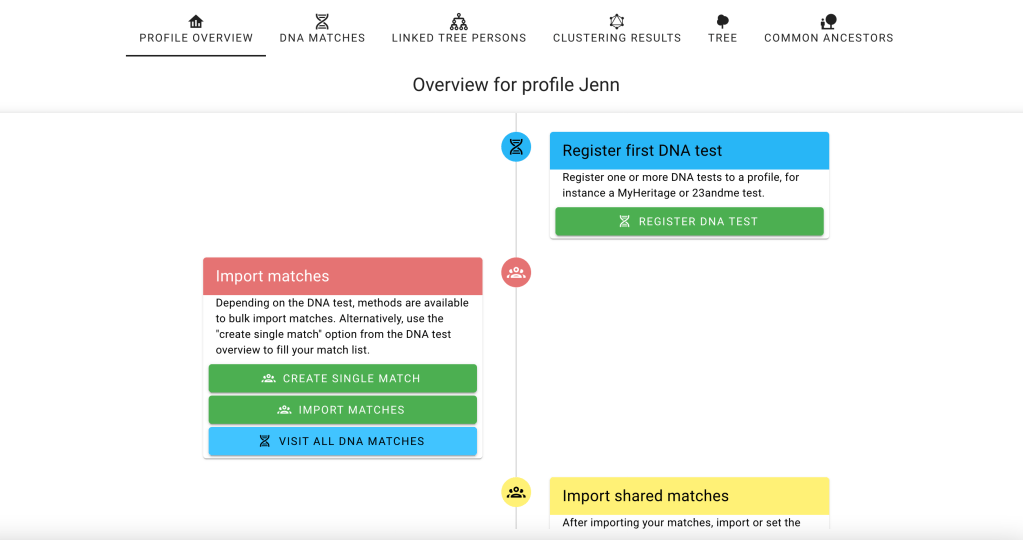
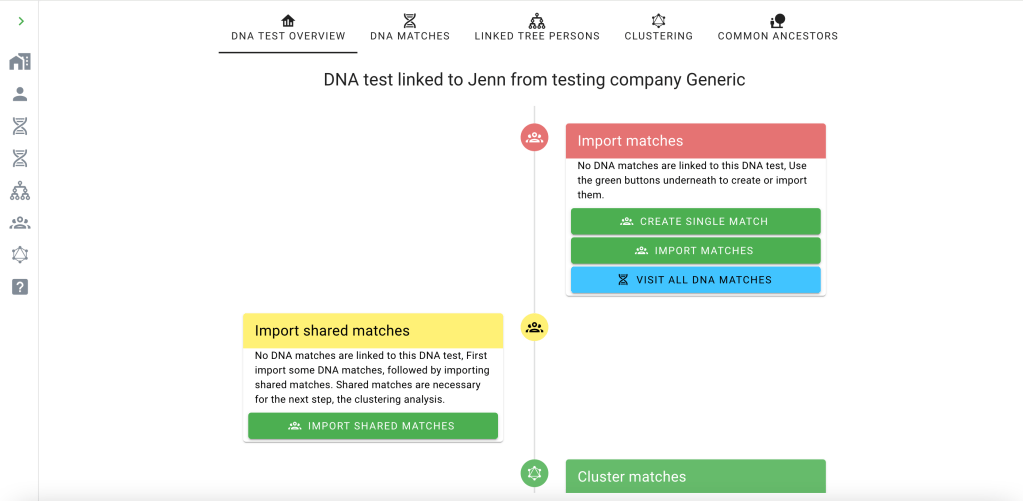
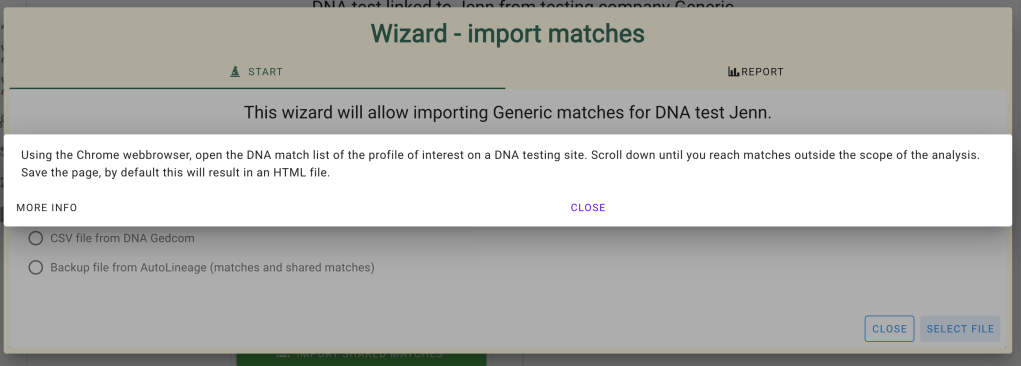
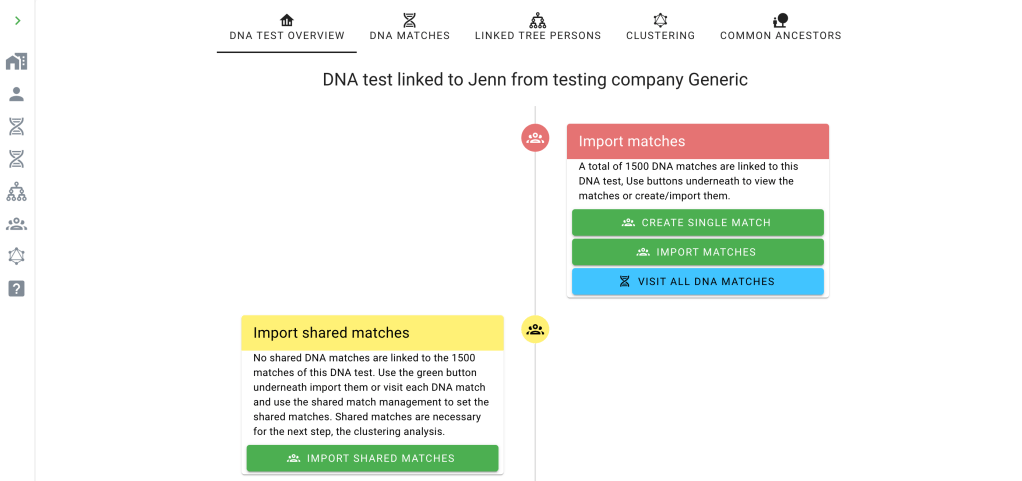
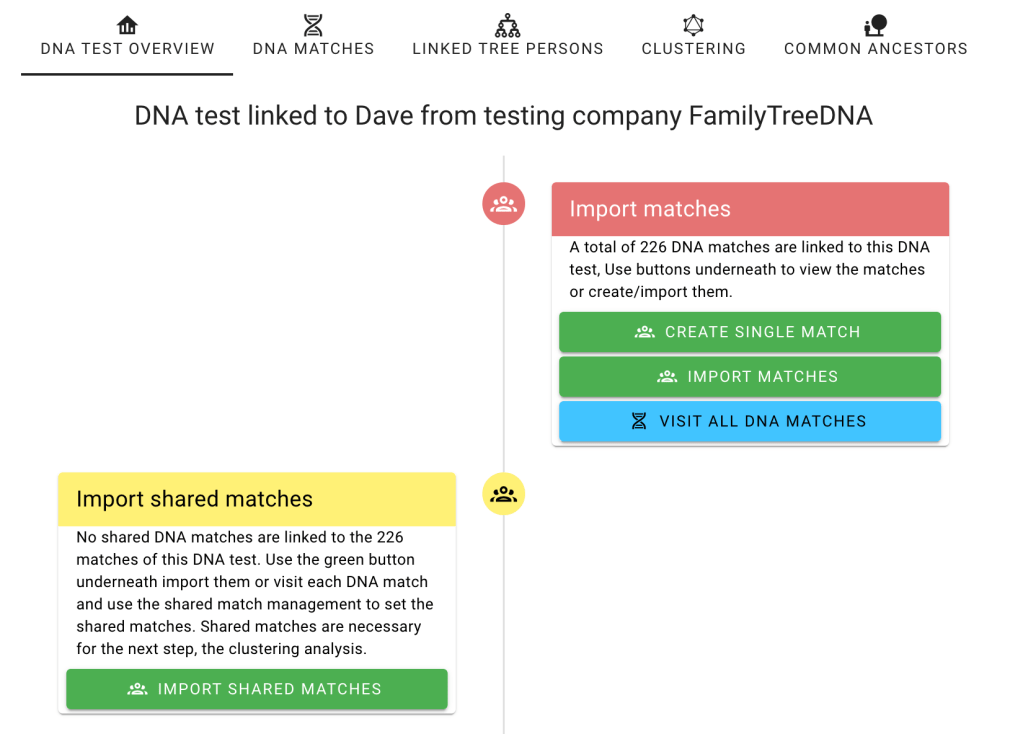
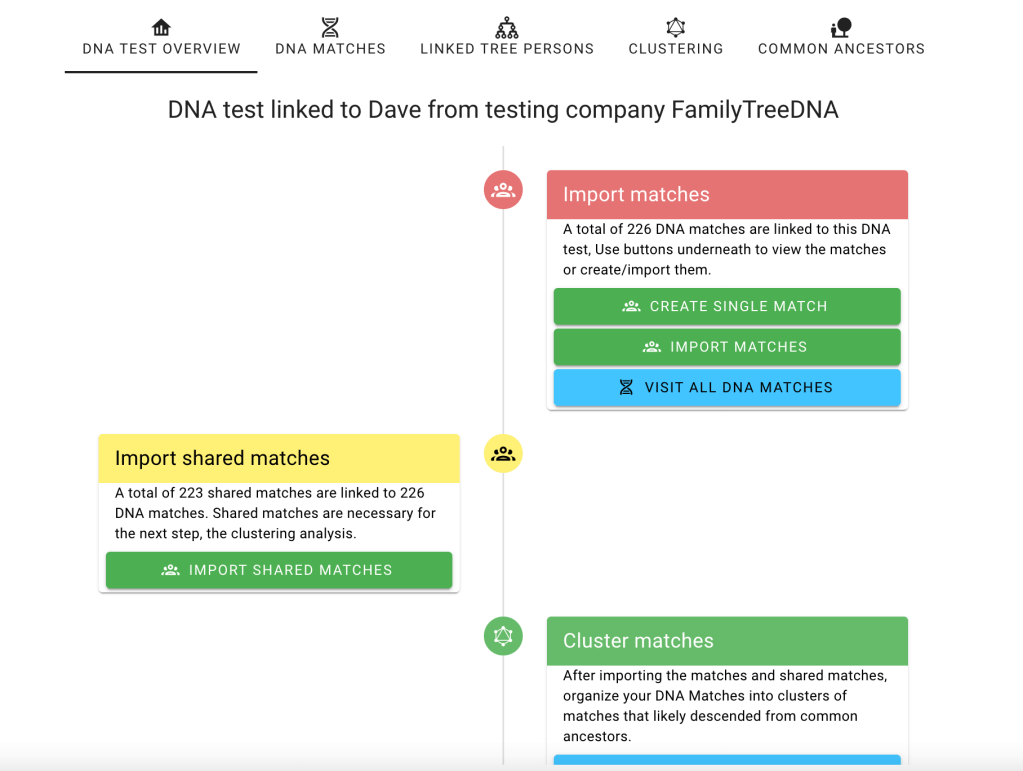
The first thing to do is to import Dave’s matches from FTDNA. Click on the ‘import matches’ button.

Flowchart showing Import matches.
Each testing site has its own list of methods for collecting matches.

Here we are using the first one, a CSV file from Genetic Affairs. Clicking on the question mark explains what file this option needs.

For this option, we first ran the AutoCluster analysis with the AutoTree feature enabled for FTDNA on Genetic Affairs.

After starting the analysis, an email appeared with a download link. Alternatively, this link is also available in the notification section on the members page of Genetic Affairs (top right corner, under the bell icon).
After unzipping the results file, we found all the data we needed for AutoLineage. In the Gephi folder, two files are present; nodes.csv and edges.csv. The nodes file contains the matches that would be selected in the dialog box of the ‘Wizard – import matches’.
The imported DNA matches are shown after the import process has been completed.

Clicking on ‘DNA test overview’ at the top brought back the flowchart where we selected ‘Import shared matches.’. Shared matches are required for the clustering process.
The wizard explains that the edges.csv file from the Gephi folder is used for the shared matches.

After importing the shared matches, which can take some time, the number of shared matches for each match is now displayed in the table.
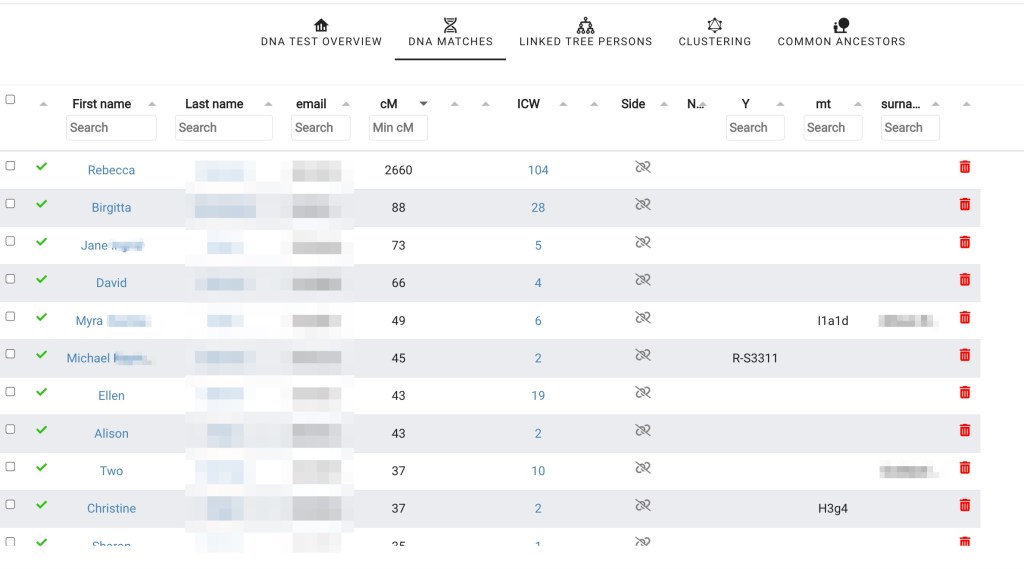
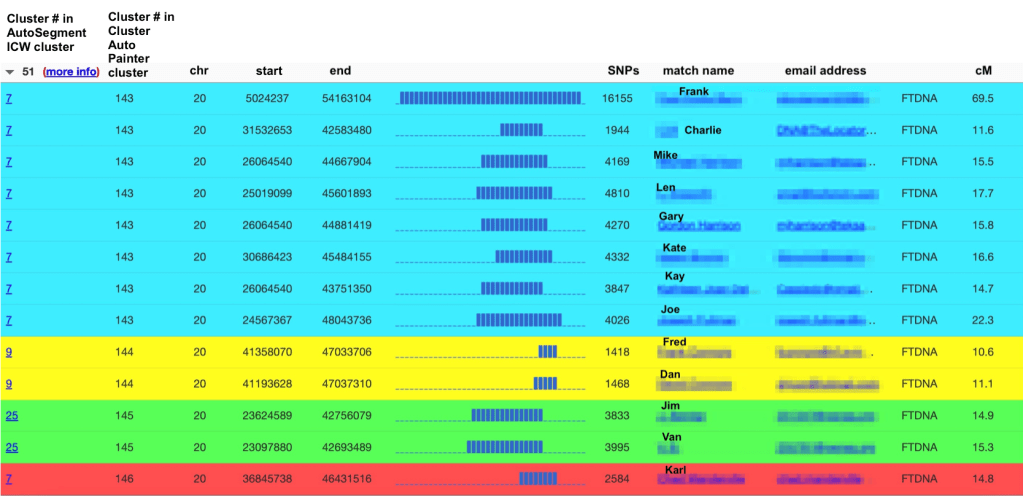
With matches and shared matches available, we ran the cluster analysis for FTDNA. Going back to the ‘DNA test overview’ brings up the flowchart where we selected ‘Cluster matches.’
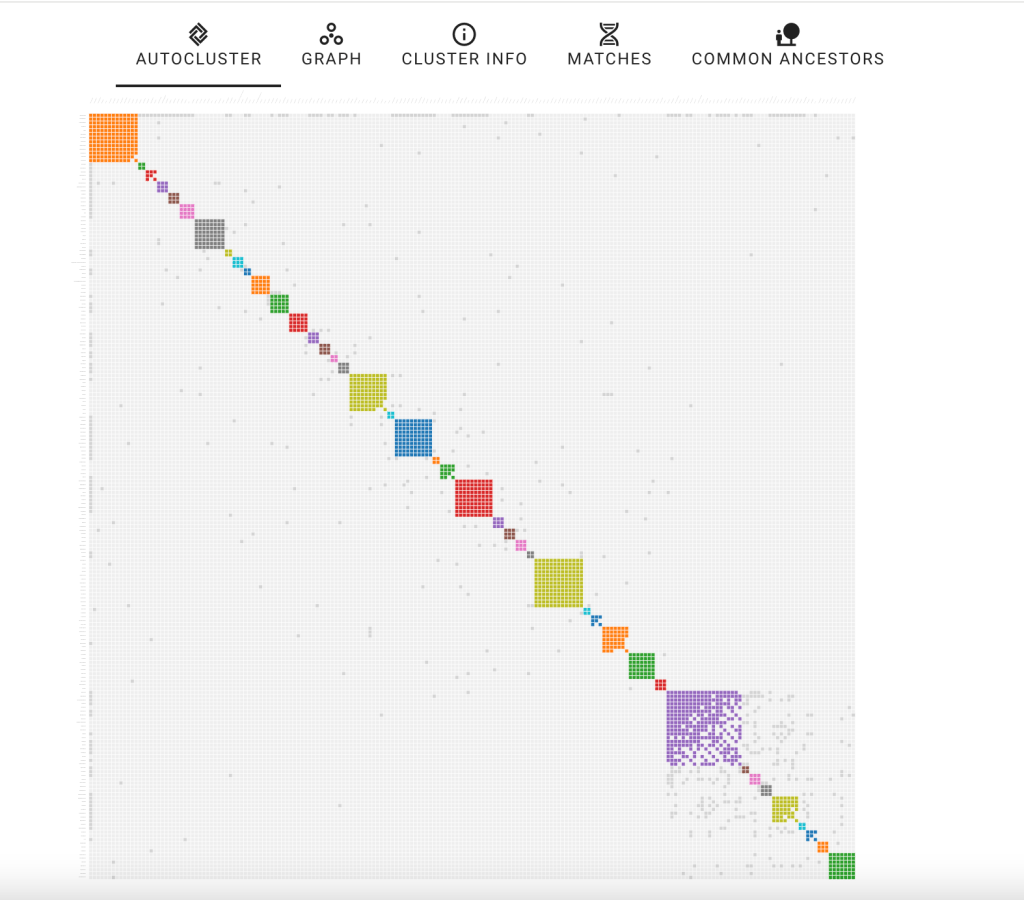
The ‘Clustering wizard’ allows us to select the range of matches for the clustering, which type of clustering, and which color scheme should be used.

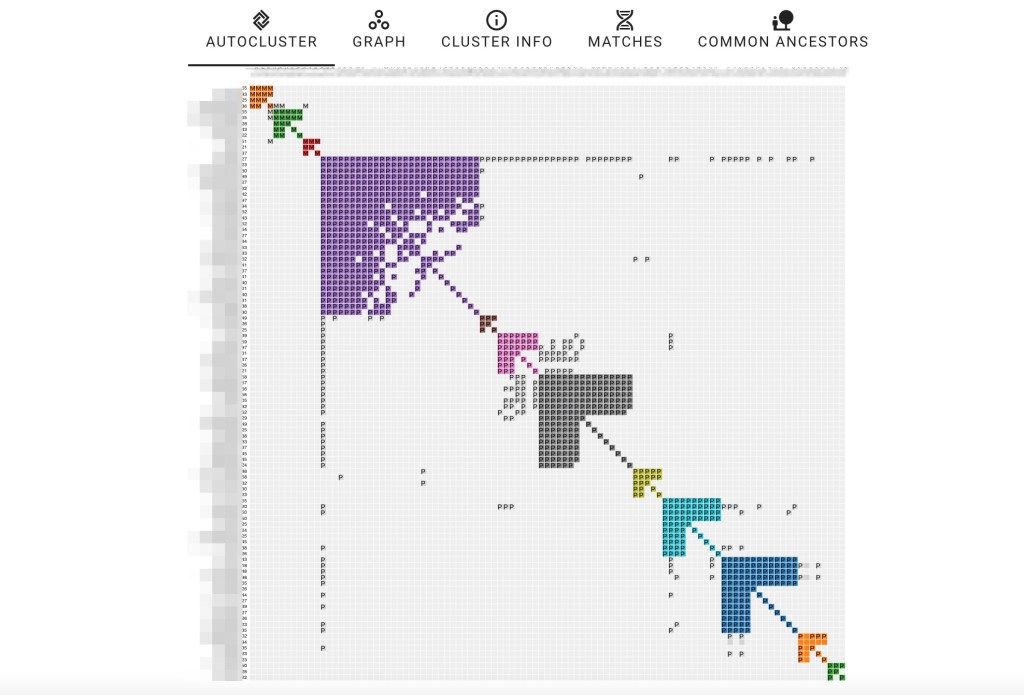
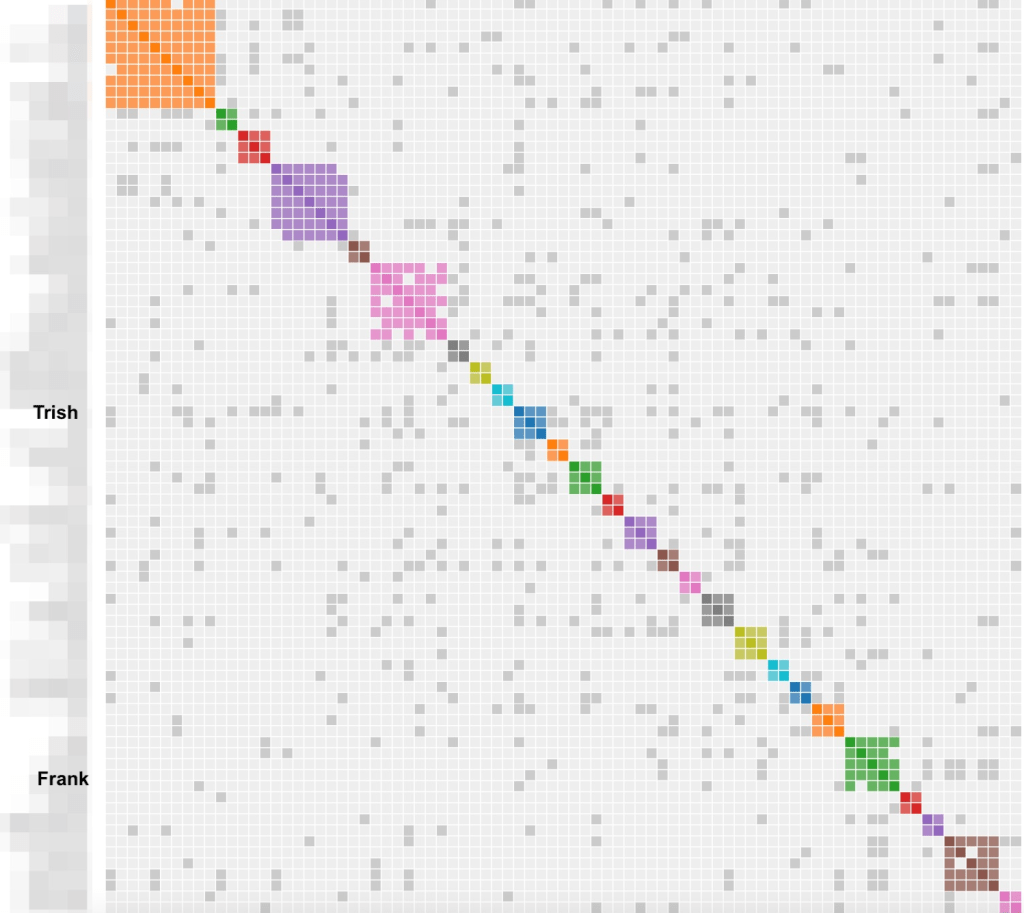
We selected to run all of Dave’s matches in the clustering analysis. After selecting the “start clustering” button, the clustering chart appears.
GEDmatch
For the GEDmatch data, we added data from an AutoKinship analysis (Tier 1).
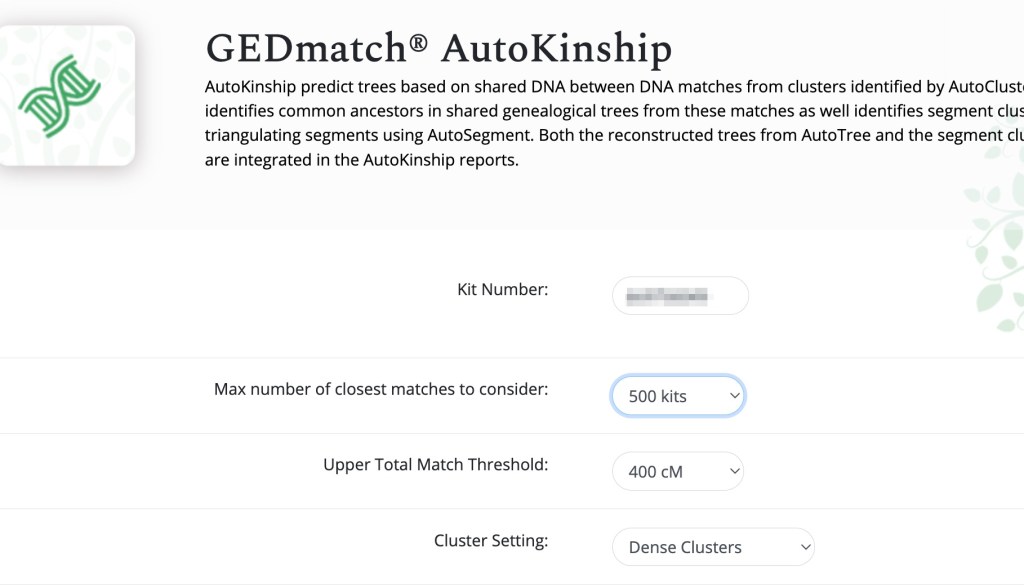
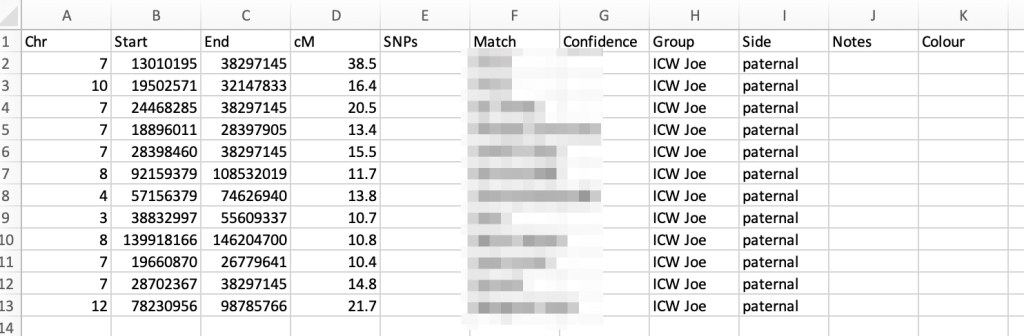
Going back to Dave’s profile page we registered another DNA test and selected GEDmatch from the drop-down list. Next we ‘import matches.’ An unzipped AutoKinship report also has a Gephi folder containing the nodes.csv and edges.csv files. Nodes.csv contains Dave’s matches, and edges.csv contains the shared matches. Now these matches can be clustered. We ran 500 kits for AutoKinship and 362 of these have shared matches.

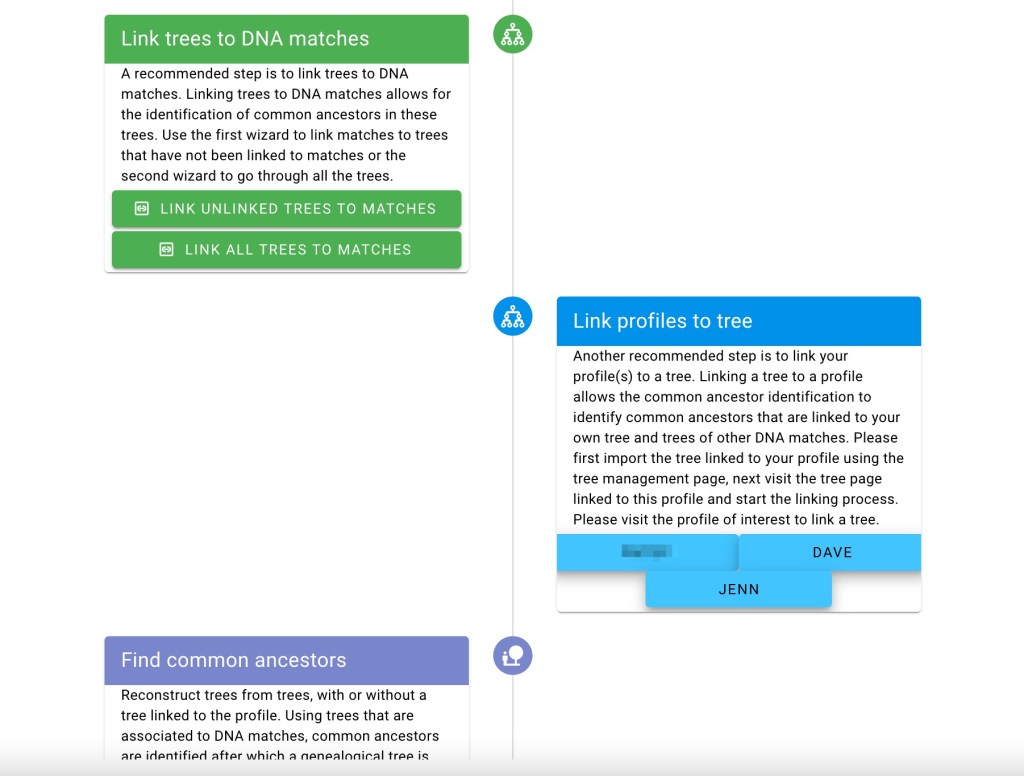
Adding Trees
Now it’s time to add trees. The trees are typically associated with the matches, but they are managed independently of the DNA testing site. Clicking on ‘Home’ in the left panel brings up a list that includes ‘Tree Management.’ Clicking on ‘Tree Management’ brings up the flowchart for Trees.

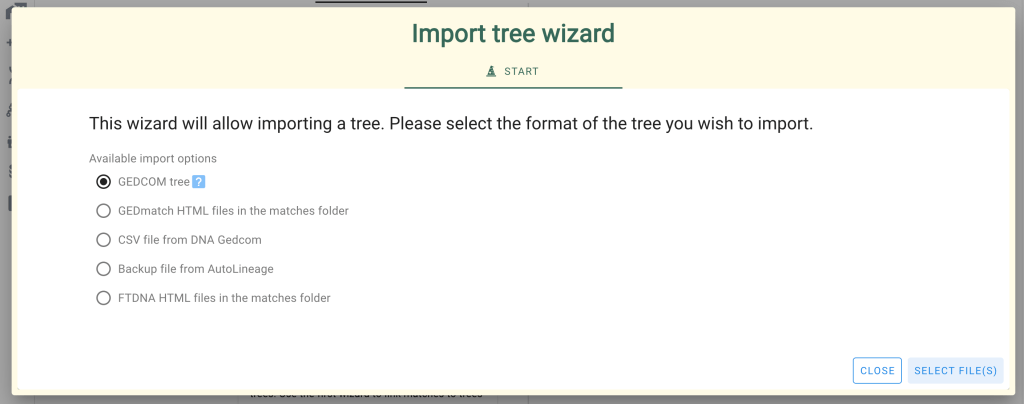
In ‘Gather Trees’ we clicked on ‘Import Trees’ which brought up the ‘Tree Wizard.’ There is a setting for the trees associated with the GEDmatch DNA matches, and a different setting for trees associated with the FTDNA DNA matches. In both cases, they retrieve tree information from the ‘match’ files associated with the GEDmatch AutoKinship or the FTDNA AutoTree AutoCluster.

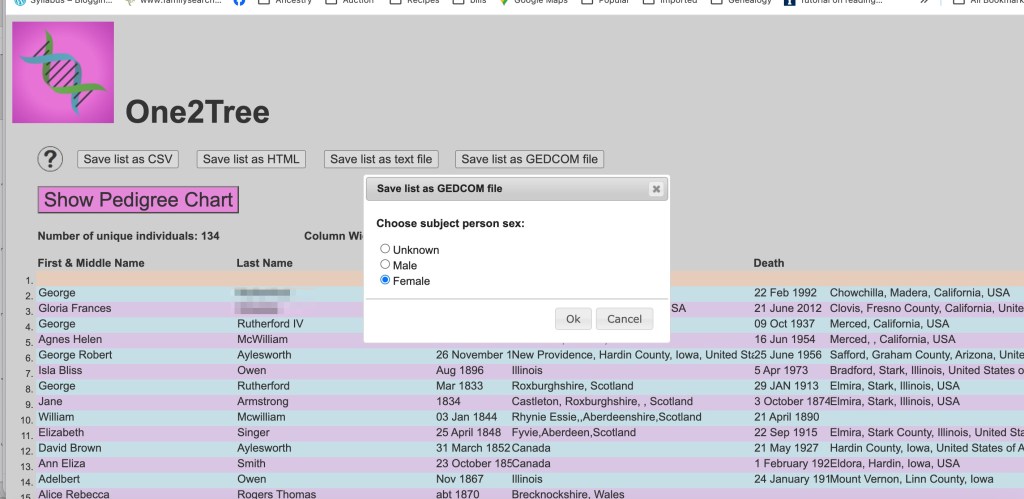
In both scenarios, we selected all the HTML files in the match folder of the unzipped AutoCluster FTDNA report or unzipped AutoKinship GEDmatch report. Using these methods also ensured that the trees were automatically associated with the FTDNA and GEDmatch DNA matches
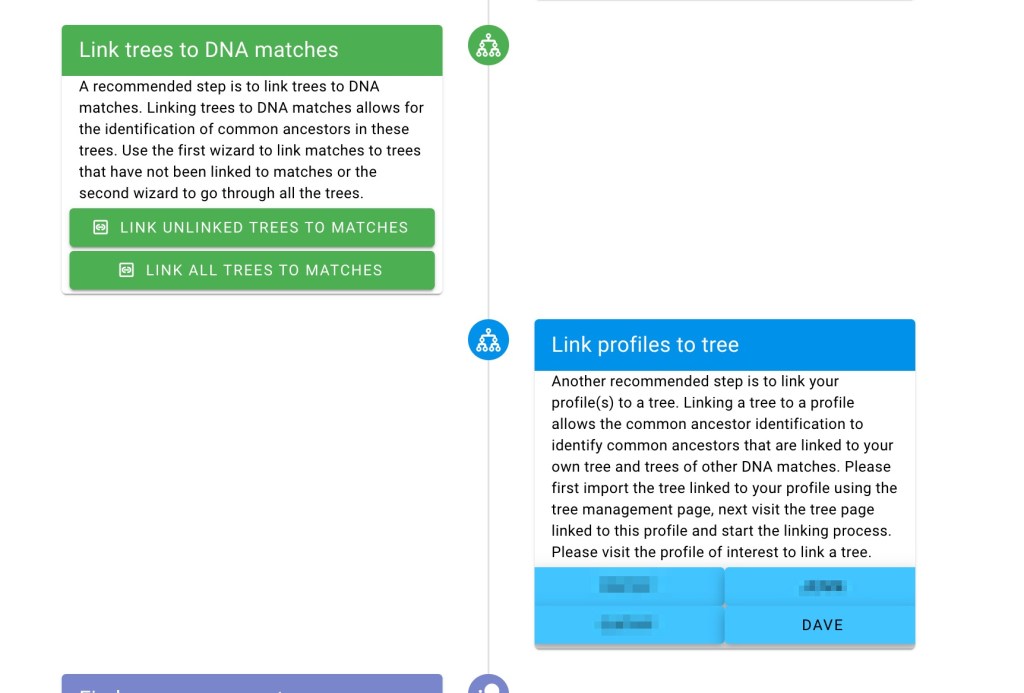
Typically, iGG profiles are not associated with trees, but in our example, Dave does have a tree, and it needs to be linked to his profile. For other cases where the tester does not have a tree, such as people looking for birth parents, this step would be skipped, and you’d go on to ‘Find Common Ancestor’ from the various DNA matches.
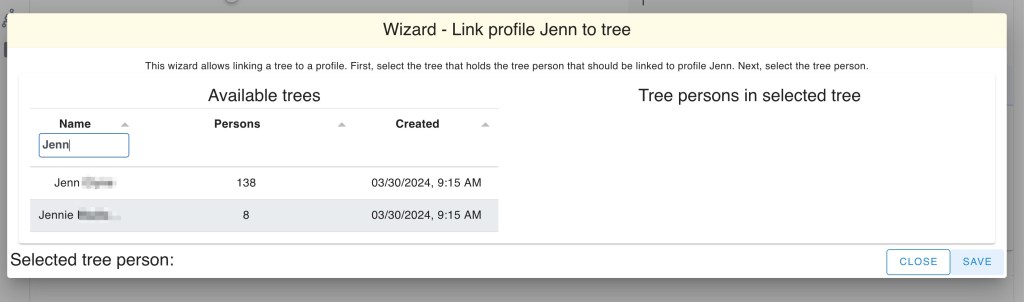
To link Dave’s profile to a tree, we visited the tree management and select Dave in the ‘link profiles to tree’ section (alternatively, go to the tree view in Dave’s profile and associate the tree from there).
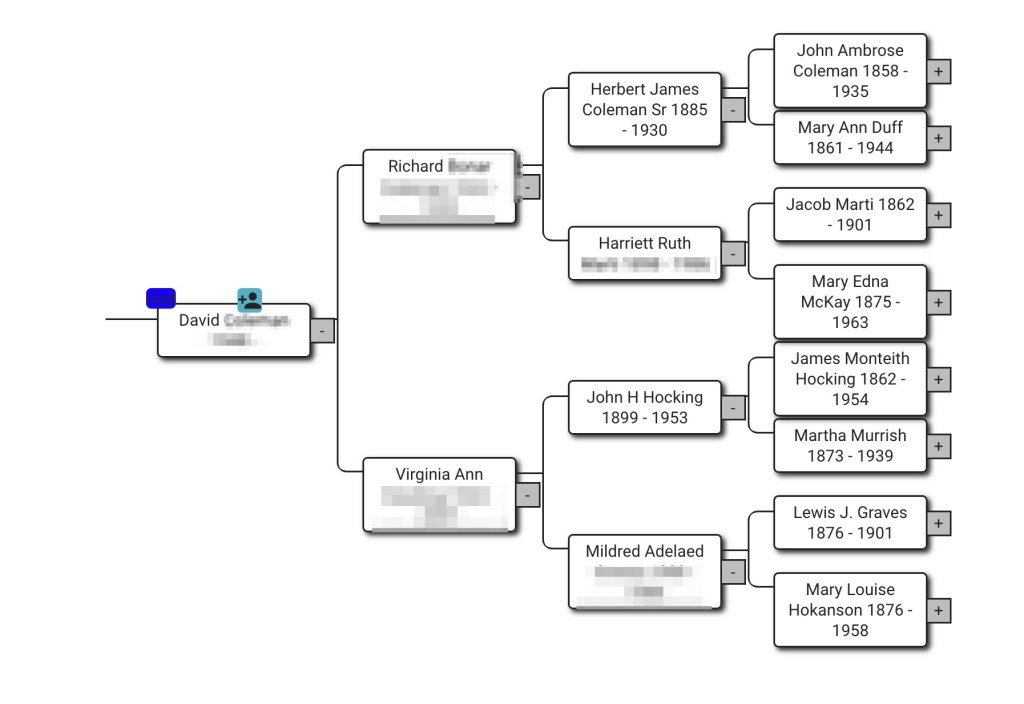
We clicked on Dave’s name and brought up the Wizard to link Dave’s profile to his tree. Next we searched for Dave’s tree in the name field.

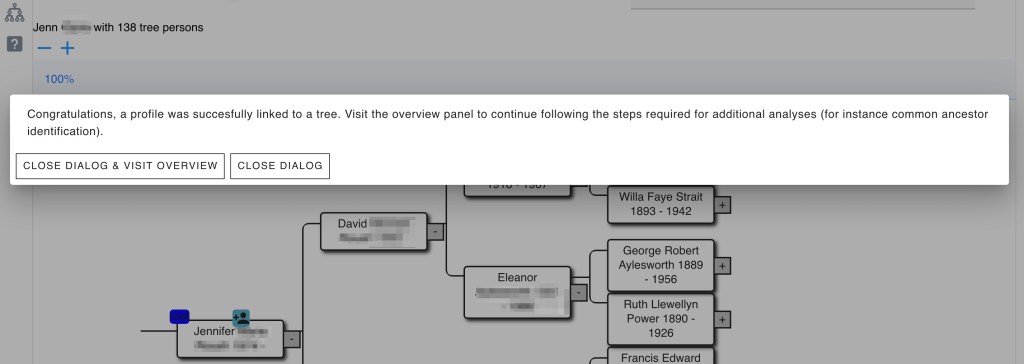
Selecting Dave brought up his tree where we selected him as the root person of the tree.

This brought up Dave’s tree. Notice the person image over Dave’s name that tells the tree is connected to his profile.
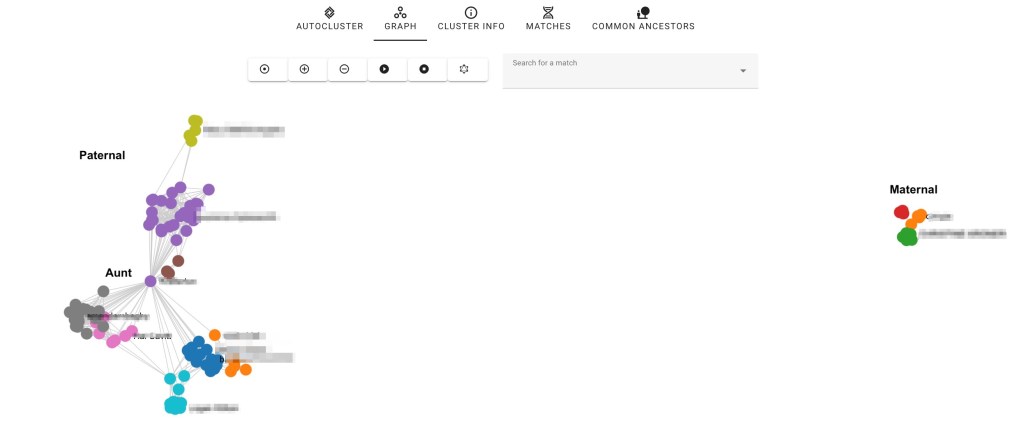
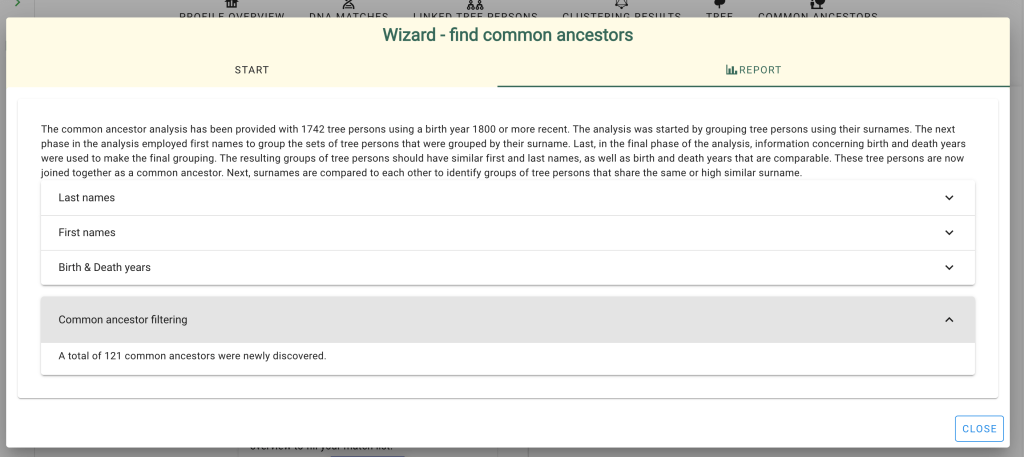
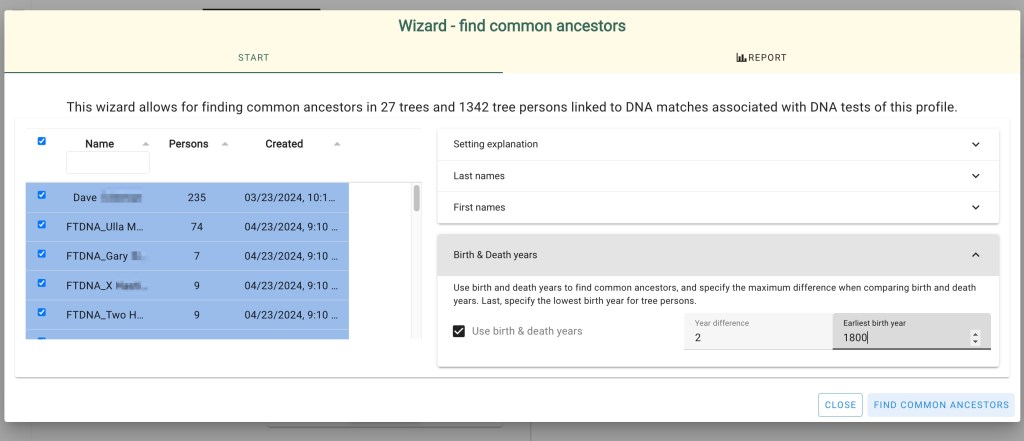
Going back to Dave’s profile page we scrolled down to ‘Find Common Ancestors’ near the bottom of the page. There are now two DNA tests associated to his profile, and some of the DNA matches are linked to trees that we imported. We selected the ‘find common ancestor’ button to start the common ancestor wizard.

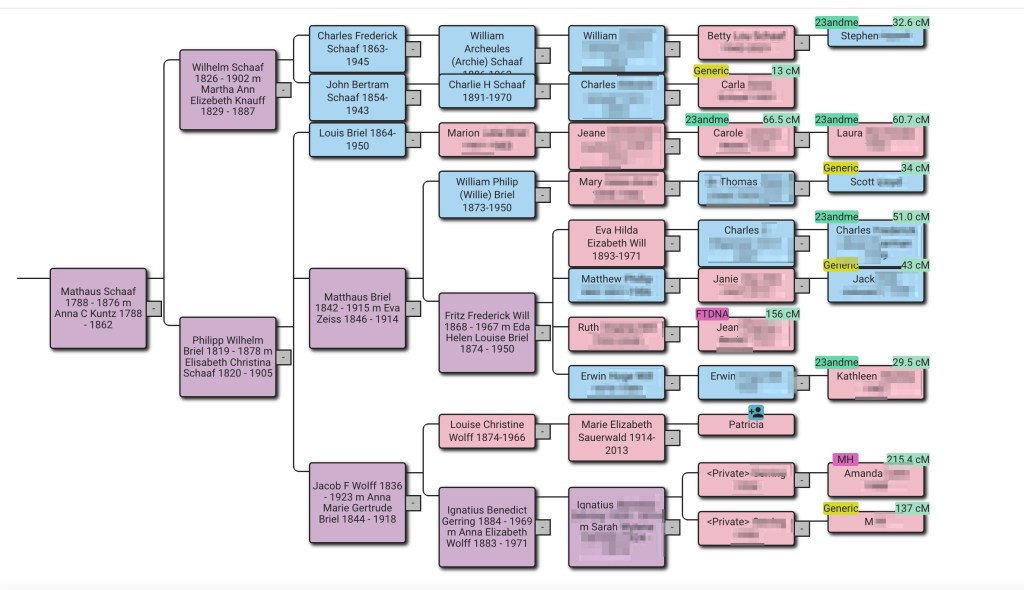
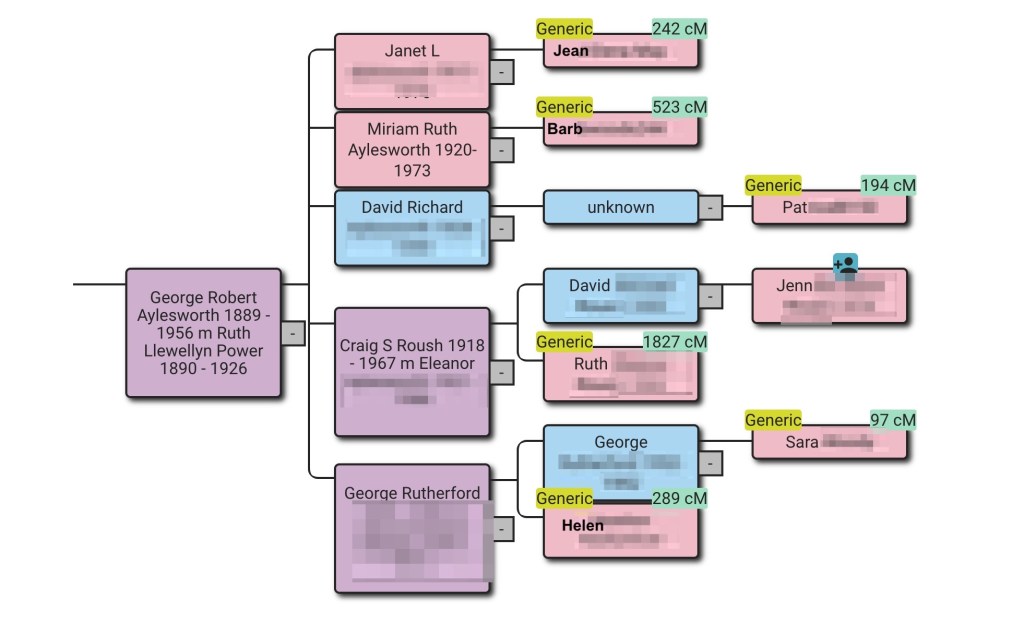
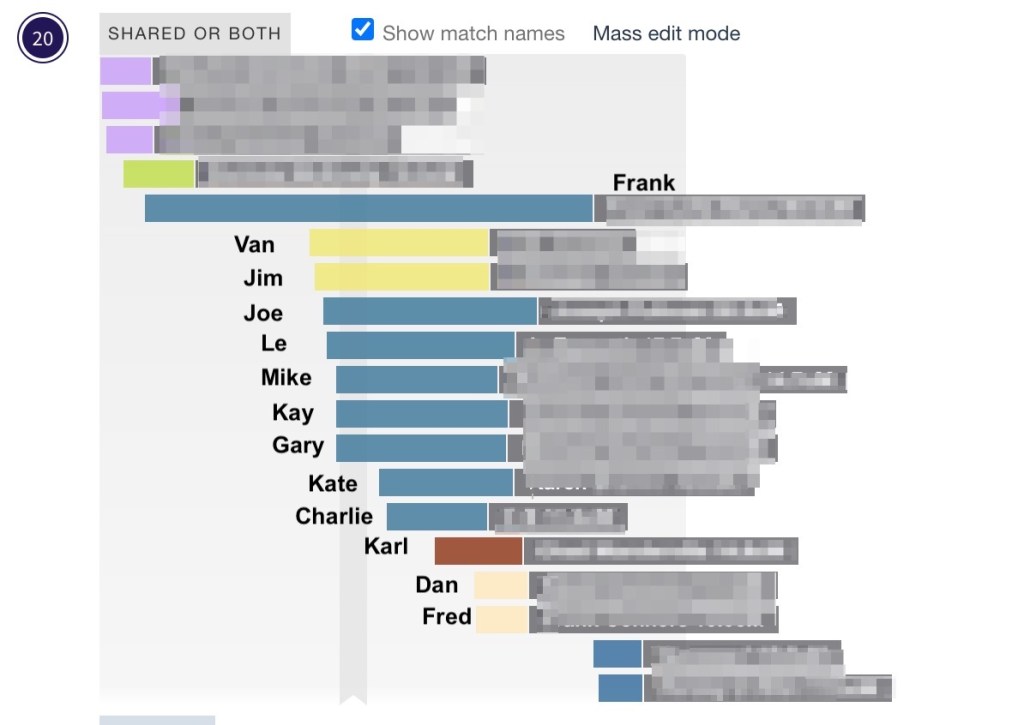
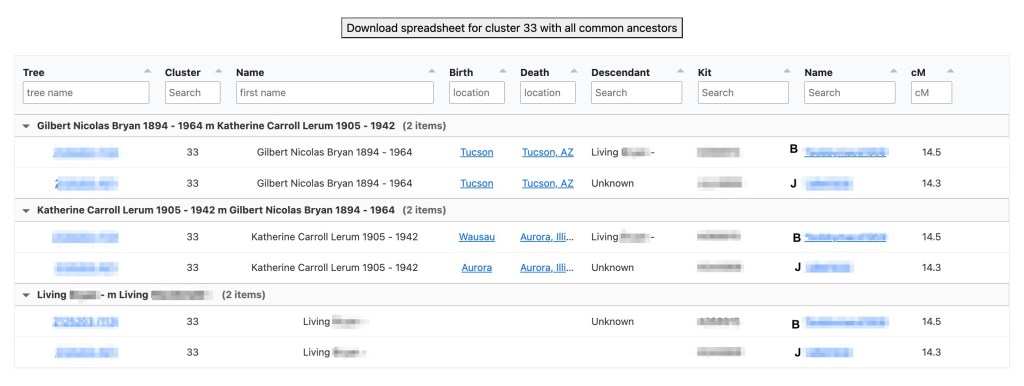
Running the analysis with the default birth year of 1800 identified eighty-seven common ancestors for Dave across FTDNA and GEDmatch. A problem arises when a match is on both sites and has a tree at both locations. The match on the right of the reconstructed tree shows both FTDNA and GEDmatch. She and her tree are duplicated which causes brown squares, indicating that tree persons are duplicated. Seeing a lot of these brown squares is often indicative of a problem.

Clicking on ‘Linked trees’ shows the trees that are attached.

Right-clicking on the tree brought it up in a new tab. Since the GEDMatch tree has more people we kept that one and deleted the FTDNA one. Next, we attached Rachel’s FTDNA DNA match to the remaining GEDmatch tree.

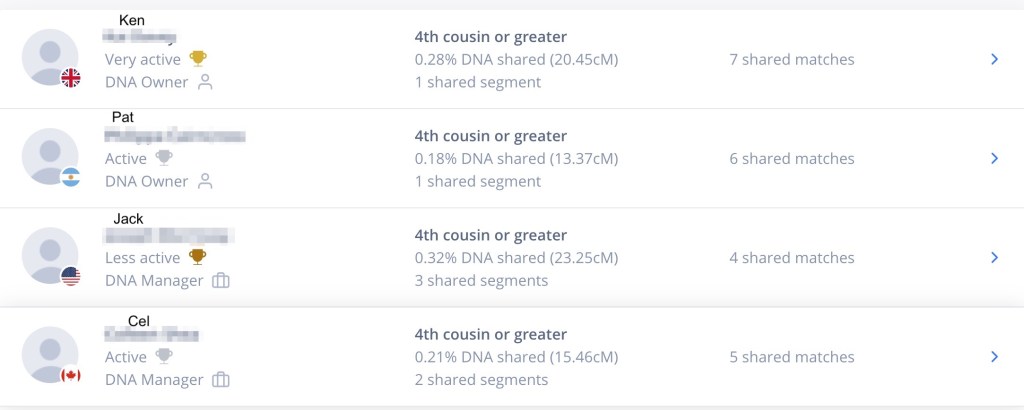
Rachel shared 30 cM with Dave at FTDNA and 27.7 cM at GEDmatch. Looking through the list of matches in the Wizard there’s only one Rachel that matches Dave at FTDNA with 30 cM, so we selected that one.

Finding Hints
Since Rachel was the only match on both FTDNA and GEDmatch we used her tree and ‘calculate hints.’

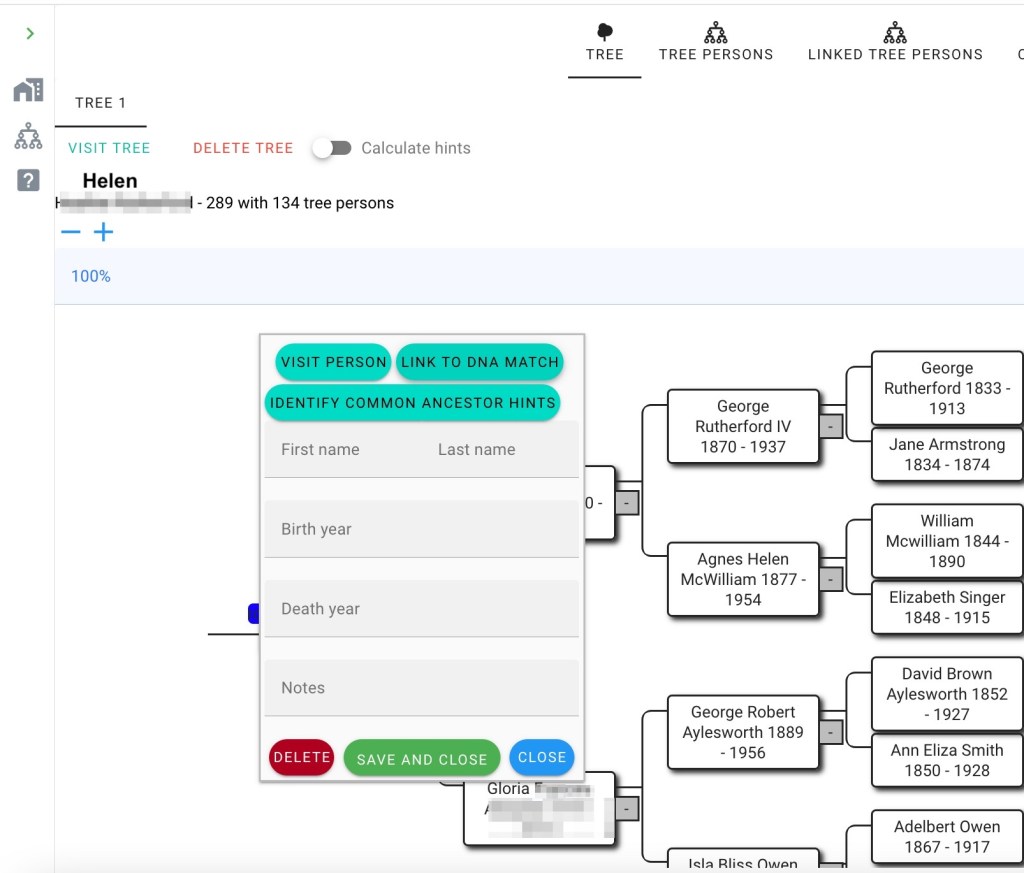
Calculate hints is basically a common ancestor identification with a focus on the tree that is shown on the screen. The tool compares the names and dates in Rachel’s tree with all the other trees that have been loaded into AutoLineage. It can take a minute or so for this calculation depending on how many trees there are. Contrary to the regular common ancestor tool, the hints tool also shows hints about shared surnames and/or surnames and first names.
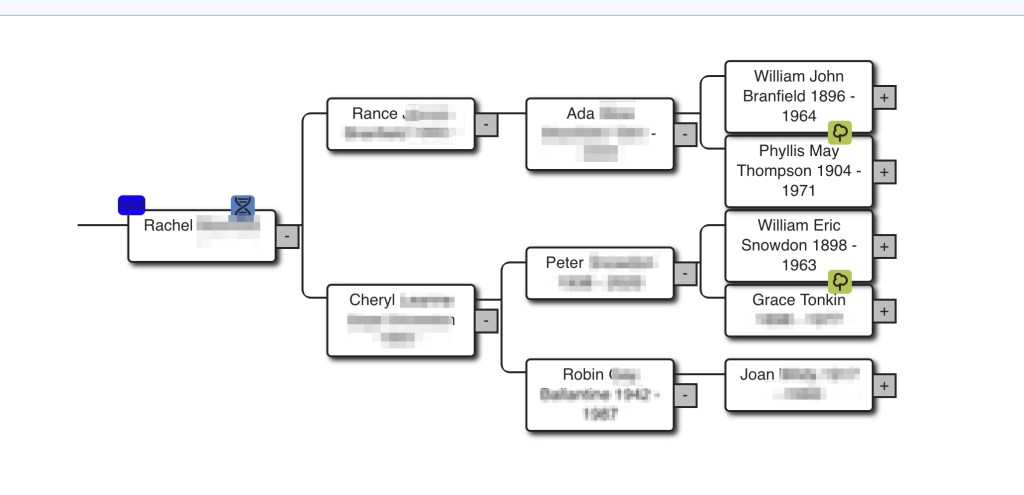
The calculate hints from Rachel’s tree showed a yellow hint for Phyllis May Thompson and for Grace Tonkin. Yellowish hints indicates a shared surname and might mean that there might be something useful farther back in time. So we expanded the tree out first from Phyllis. The common surname, Barrett, was found in another DNA match’s tree, but the dates were several hundred years different. Next we looked at the hint for Grace.

Grace Tonkin’s hint showed that Dave had several people in his tree with the Tonkin surname, but her date is more recent than the people in Dave’s tree. We followed the Tonkin line past Grace in Rachel’s tree and found that Thomas Tonkin’s dates were in the same range as those in Dave’s tree.

Thomas Tonkin’s wife, Margaret Hattam, also has a hint.

Looking at Margaret Hattam’s hint we find that Dave’s tree has several Hattam ancestors.

Margaret Hattam was born in 1785 and Dave has an ancestor, Mary Hattam born in 1783. When we added Margaret’s parents to our tree, and rerun the hints tool we found new green hints linked to Margaret’s parents.

John Hattam and Elizabeth Eddy both have green hints.
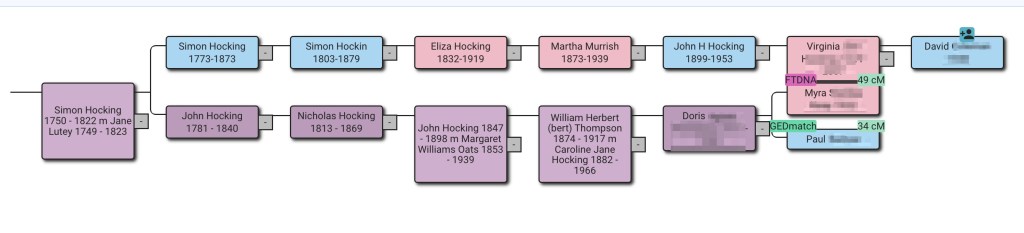
Looking at John Hattam’s hint we found that he is in both Rachel’s tree and Dave’s tree. We’ve found the common ancestor!

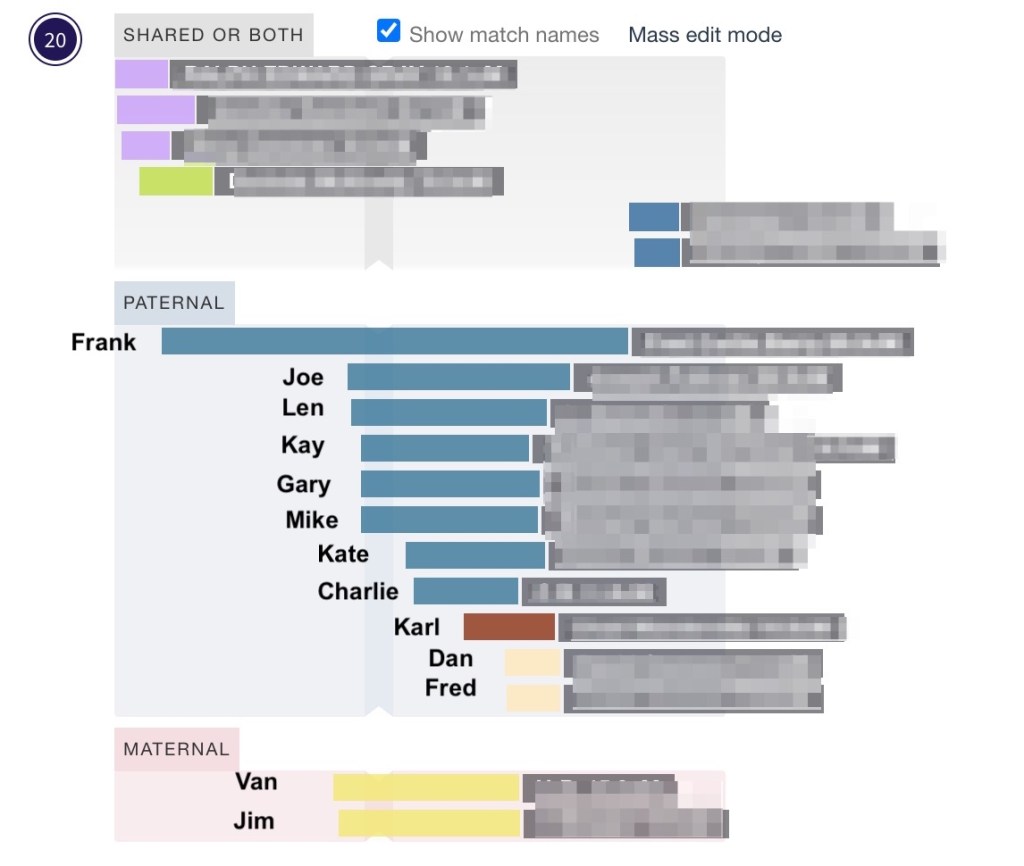
Since John Hattam had a birth date of 1754, we changed the birth year to 1700 in the parameter of the ‘Find Common Ancestors’ wizard and then reran ‘Find Common Ancestors.’
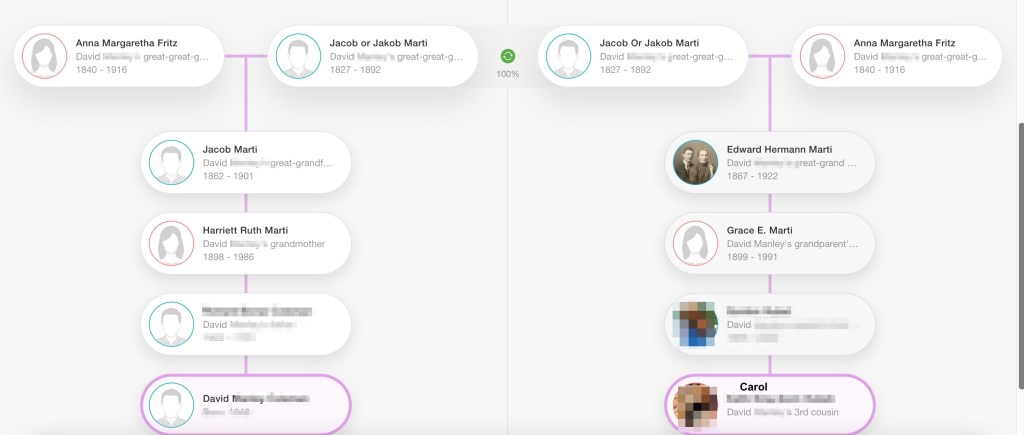
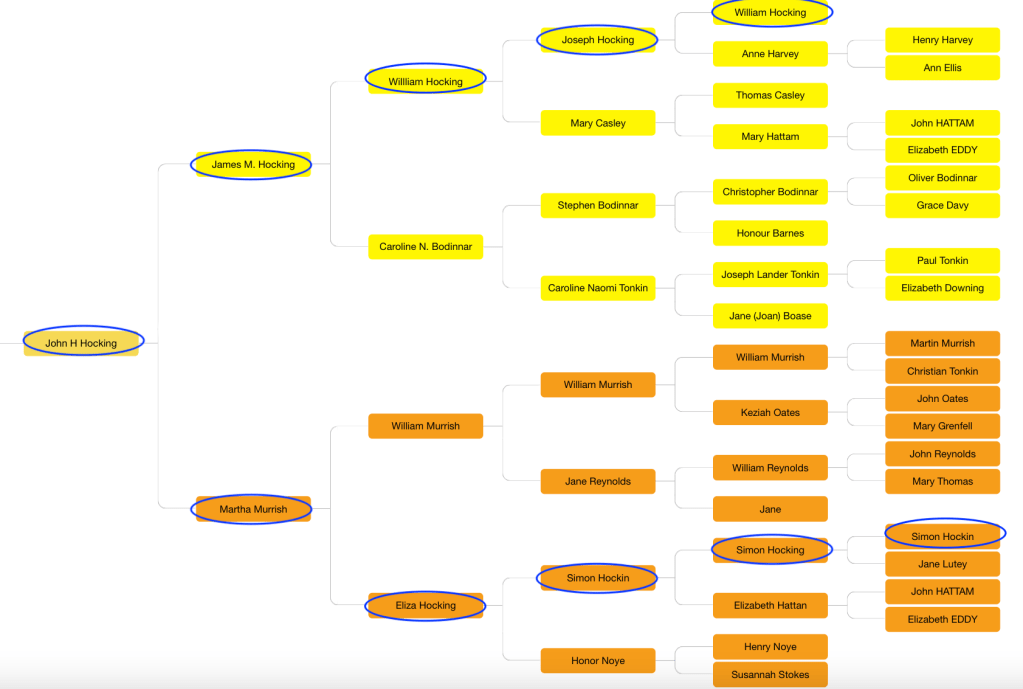
Now a total of fifty-four ancestors were found, and the reconstructed tree showed the connection between Dave and Rachel. They have common fourth great-grandparents, John Hattam and Elizabeth Eddy.
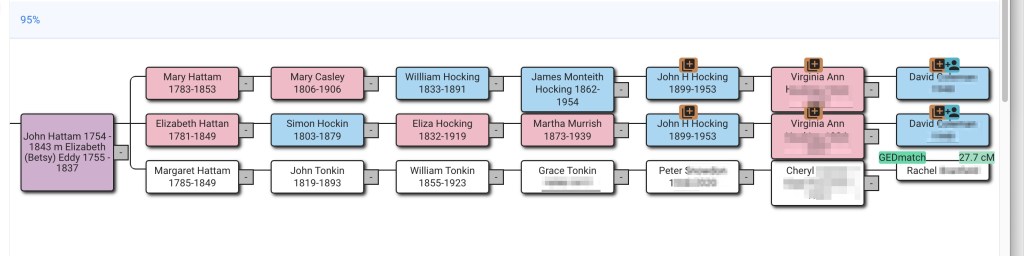
Dave’s tree is showing brown squares which often means there is a duplicate tree or a date problem, however for Dave’s family this is correct. He has two Hocking lines. John Hocking’s parents were James Monteith Hocking and Martha Murrish. James Monteith is one of the Hocking lines, and Martha’s mother was Eliza Hocking, which is the other Hocking line. They both go back to John Hattam and Elizabeth Eddy, so they are Dave’s fourth great-grandparents twice!
Summary
We ran AutoLineage using only FTDNA and GEDmatch data to look for common ancestors to Dave and his matches. AutoLineage generated clusters for the FTDNA matches and also for the GEDmatch matches. Trees from both testing sites were loaded and attached to the DNA matches. Next, we identified common ancestors across all of the data. We found one match who had a tree on both sites. By associating her DNA from both sites to one tree and deleting the extra tree we avoided her showing as a common ancestor to herself. Next, we ran hints on her tree to get clues on which ancestral lines to prioritize for our research. After expanding the tree, and re-running the hints tool, we found the common ancestor. This led us to find that she and Dave had common fourth great-grandparents!