For over two years Genetic Affairs has provided the AutoCluster reports in the HTML format. For some of these reports, it would be interesting to extract the DNA match information as well as the shared matches. This information could provide a head start for people that would like to run a manual AutoCluster analysis. Imagine transforming an old Ancestry analysis to Excel, add the most recent (shared) matches, and re-run the AutoCluster analysis using CSV files.
Another scenario would involve the MyHeritage AutoClusters analysis which does not allow you to change the maximum and minimum cM setting. It runs from 400 cM down for about 100 matches and to whatever minimum cM that gives. Recently I was looking at my sister-in-law1, Barb’s matches, and noticed that she had a known first cousin once removed (1C1R) who had tested. I was very interested in seeing her shared matches since we know something about Barb’s mother’s side of the family. But to my dismay, this match, Grace, matched Barb at over 400 cM and so wasn’t included in the cluster. Well, I can manually look through all 90 of her matches, or normally I’d think of Leeds method, but I know this is Barb’s mother’s father’s side of the family, and I’m more interested in who the matches are and how they connect to others in the family.
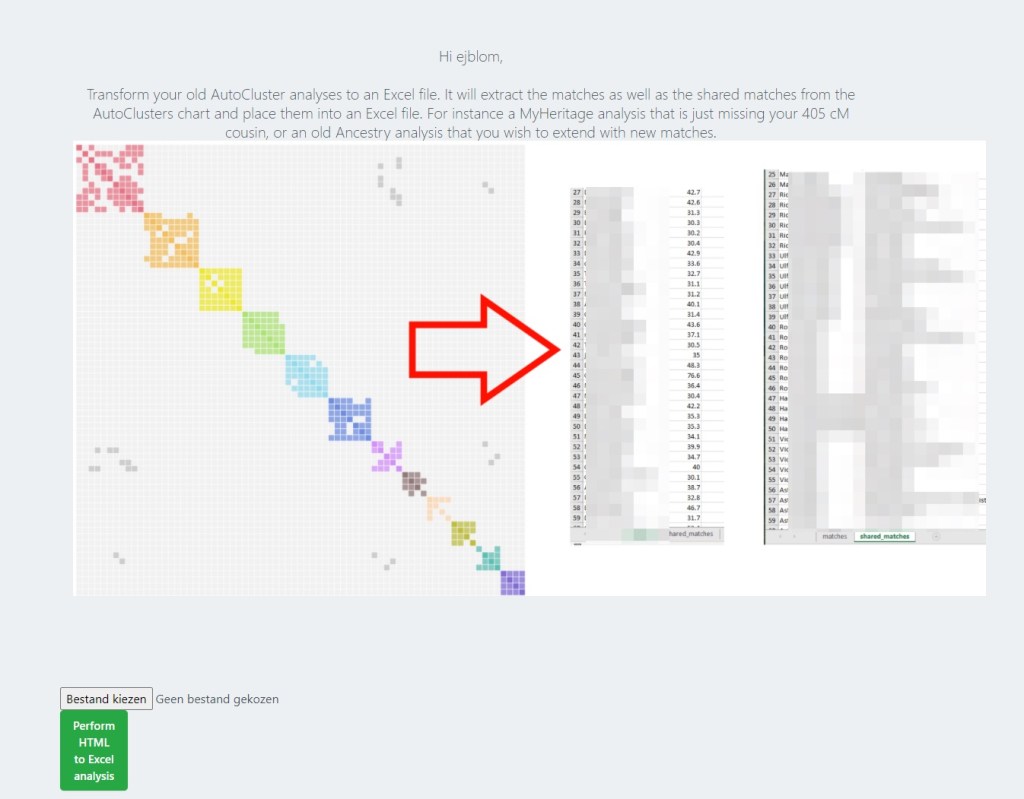
I wanted to follow Grace’s matches and compare them with the rest of the AutoCluster. There’s a new feature on Genetic Affairs that lets me do just that. ‘Transform AutoCluster HTML’, as shown in figure 1, lets me take the existing AutoCluster HTML report and convert it to an Excel file with 2 tabs. One tab has the matches with the name of the match and the cM they share. The second tab has the shared matches for all the people in the match list. Using this I can add Grace and her matches to the match list with their cM values and save that tab as a new CSV file. Then I can add Grace and her matches to the shared match list and again save that tab as a new CSV file. Next, I can run a CSV AutoCluster (as explained in an earlier blog post) using my two new CSV files and generate a cluster that contains Grace and her matches along with all the matches that were in the original MyHeritage AutoClusters.

Looking at the MyHeritage AutoCluster I noticed that it went down to 30 cM. So I’d want to find Grace’s matches that also go to 30 cM to be consistent. Looking at Barb’s matches and selecting Grace I could then see her shared matches with Barb. The shared match list on MyHeritage doesn’t always go by the highest match first and appears to have highest matches to Grace in some cases before the highest shared matches to Barb, so I went down the list making a new Excel file of the match names and the cM shared with Barb. I went down to the point where matches I was seeing were less than 20 cM. At that point I skimmed the rest of the list for any matches over 30 cM and didn’t see any. So I was pretty sure I’d found them all.
Next I downloaded the Excel file from Barb’s MyHeritage AutoCluster, see figure 2, so I could add the new matches I’d found with Grace. Even though Barb and Grace had 90 shared matches only 10 of them were over 30 cM. Then I looked at those 10 matches to see if they matched others in this little group of 10. A couple of things I noticed that turned out to be important. One is to the copy the name exactly as they listed it in MyHeritage. You and I might think that John Smith and John SMITH are the same, but the comparison won’t see it that way. The other problem I had was in writing Robert F. Jones but he had Robert F Jones without the period after the initial. Thus it took me a couple runs, because of these minor, careless mistakes to get the AutoCluster that I wanted.

Figure 3 shows the new AutoCluster with Grace in cluster #1 along with her matches. As it turned out 2 of those 10 matches did not have any shared matches over 30 cM so they were not included. That first cluster is all on the Barb’s mother’s side of family side as well as the matches in the second cluster.
Summary
Being able to convert my old AutoCluster to an Excel file and then adding new matches is a great new feature. It will be a lot easier to update older clusters with additional information without having to redo the entire cluster as a manual csv cluster.
- Barb has given me permission to use her real name.

Leave a comment